[Compiler] 1. Lexical Analyzer :: 구현하기
* 2020/04/09 - [Programming/Compiler] - [Compiler] 1. Lexical Analyzer :: 동작하는 방식에서 이어지는 내용입니다.
Lexical Analyzer를 구현해보자
무엇을 구현해야 할까?
Lexical Analyzer는 input을 읽고 토큰으로 분류를 해서 Symbol Table을 만들어야 합니다.
- Token들의 Pattern
- 그 Pattern들을 인식하는 코드
- Symbol Table
1. Token들의 Pattern은 어떻게 정의할까?
정규식(Regular Expression)을 사용하면 편합니다. 특정 문자열의 패턴을 간결하면서 정확하게 표현을 하게 해주는 좋은 도구입니다. 비교를 해봅시다.
식별자 Token의 Pattern을 글로 표현한 경우
식별자라는 토큰의 패턴은 길이가 1 이상이고 첫 번째 문자로 문자가 와야 하고 그다음 문자부터는 숫자나 알파벳이 올 수 있습니다.
식별자 Token의 Pattern을 정규식으로 표현한 경우
∑ = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z}
* 숫자=0|1|2|3|4|5|6|7|8|9
* 알파벳=a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z
식별자 = 알파벳 ( 알파벳 | 숫자 )*
2. 정규식을 인식하는 코드를 어떻게 구현할까?
이미 저 정규식을 입력을 받아서 특정 문자를 찾거나 확인하는 툴들이 시중에 많이 나와 있습니다. 하지만 이번 글에서는 그러한 툴을 사용하지 않고 모든 것을 외부의 코드 없이 구현해보도록 하겠습니다. 정규식은 Finite Automata와 100% 호환됩니다. 단지, 정규식은 특정한 단어들의 패턴을 표현하는데 유리하고 Finite Automata는 그 문자열을 인식하는지 인식하지 않는지 알려주는데 유리합니다. 그렇기 때문에 우리는 정규식을 Finite Automata로 먼저 바꿔야 합니다.
Regular Expression를 Non Deterministic Finite Automata(NFA with epsilon)로 변환하기
Thompson's Construction을 사용하면 기계적으로 정규식을 입실론이 있는 NFA로 바꿀 수 있습니다.
Non Deterministic Finite Automata(NFA)를 Deterministic Finite Automata(DFA)로 변환하기
위의 입실론이 있는 NFA를 사용하여도 정규식을 인식하는 코드를 구현할 수 있습니다. 하지만 Non Deterministic하기 때문에 하나의 Input에 여러 가지의 Ouput이 나올 수 있습니다. 그래서 효율적이지 않습니다. 그렇기 때문에 NFA를 Deterministic하게 바꿔줄 필요가 있습니다. 그리고 다행히 NFA와 DFA는 표현 능력이 같습니다. NFA를 DFA로 바꿔줄 때는 Subset Construction을 사용하면 바꿀 수 있습니다.
DFA를 코드로 구현하기
- DFA가 가진 state를 enum과 같은 자료형으로 다 정의합니다. 아니면 string으로 정의해도 되고 선택지는 많은 것 같습니다.
- Transition Table을 만듭니다. (현재 state에서 특정한 input을 받았을 어떤 state로 이동해야 되는지 알려주는 tavle)
- Transition Table을 이용해서 현재 state와 현재 input을 주면 내가 이동해야 되는 state를 반환해주는 함수를 만듭니다. (잘 설계하면 2랑 3이랑 합칠 수도 있습니다.)
- Final state로 왔는지 감지하는 함수도 만듭니다. (함수를 안 만들어도 됩니다. Final state 즉, Accept 했는지 인식하는 것을 구현만 하면 됩니다)

그러면 Regular Expression을 인식하는 Finite Automata가 코드로써 완성됩니다!
실제로 사용하기 위한 DFA를 코딩해봅시다
무엇을 구현해야 할까요?
사람마다 생각하는 것이 다를 것 같습니다.
State나 Alphabet을 정의하지 않은 아주 간략화된 버전의 DFA를 코딩하는걸 예시로 보여드리겠습니다!
DFA 객체
Method
LoadTransitionTable: Regular Expression의 Transition Table(DFA) 가져오기PeekNextState: 다음 State로 뭐가 나오는 보기 = delta FuctionGetState: 현재 State 반환SetState: State 설정GetToken: 현재 분류된 Token 반환IsAccepted: Accepted(Final) State인지 반환Reset: 초기 상태로 초기화한다
Attribute
currentStatetableacceptedStates
ex) 산술 기호를 인식하는 DFA를 구현해봅시다.
산술 기호는 +, -, 입니다. 정규식으로는 다음과 같이 표현할 수 있습니다.ArithmeticOperators = + | - | * | /
- 정규식을 Thompson's Construction을 사용해서 DFA로 변환합니다
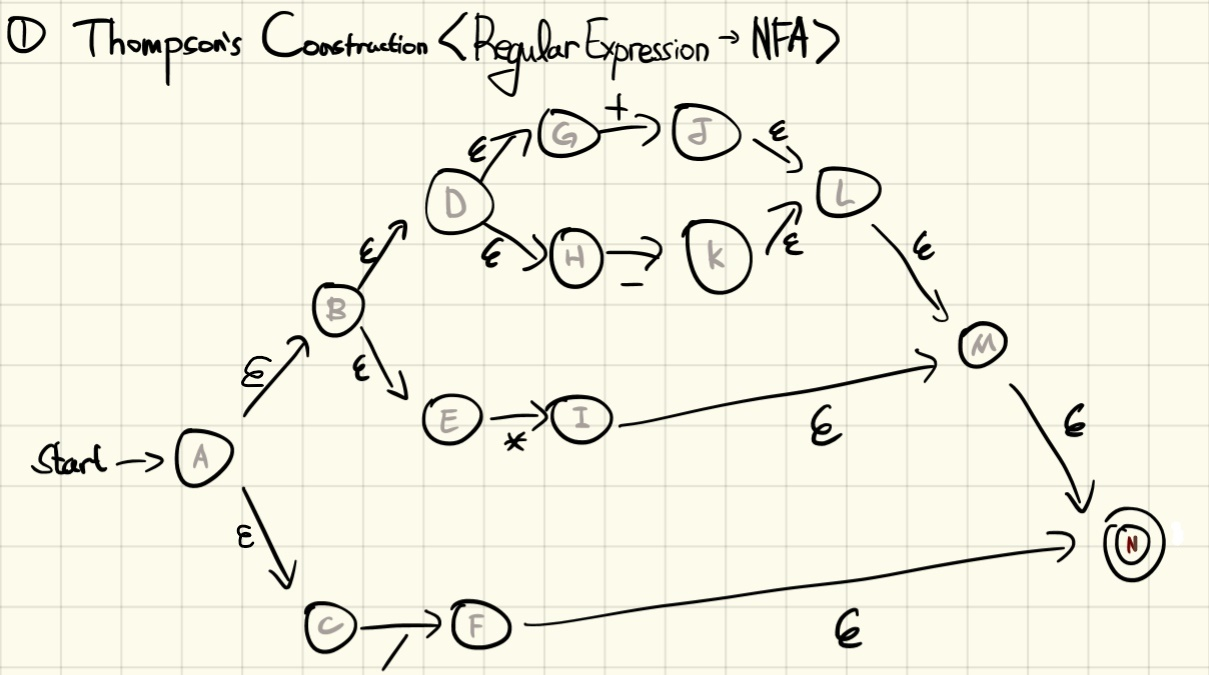
- DFA를 Subset Construction을 사용해서 NFA로 변환합니다

- DFA를 Transition Table로 표현합니다

다음의 Transition Table을 그대로 코드로 옮겼습니다. ARITMETIC_OPERATOR라는 Dictionary라는 형태로 Accepted State와 Token 종류와 Delta Fuction(Transition)을 표현했습니다. FiniteAutomaton은 그 Transition Table을 Load해서 동작하도록 합니다.
class FiniteAutomaton:
def __init__(self):
self.table = {}
self.currentState = "T0"
self.acceptedStates = {}
def LoadTransitionTable(self, _dfa):
self.table = _dfa["Table"]
self.acceptedStates.update(_dfa["AcceptedStates"])
def PeekNextState(self, _input):
if not _input in self.table[self.currentState]:
print("Unknown Input Symbol is Given.")
exit()
nextState = self.table[self.currentState][_input]
if nextState == "":
return "Rejected"
else:
return nextState
def GetState(self):
return self.currentState
def SetState(self, _state):
self.currentState = _state
def GetToken(self):
if self.currentState in self.acceptedStates:
return self.acceptedStates[self.currentState]
else:
return "Unknown Token"
def IsAccepted(self):
if self.currentState in self.acceptedStates:
return True
else:
return False
def Reset(self):
self.currentState = "T0"
# Transition Table of Arithmetic Operator DFA
ARITHMETIC_OPERATOR = {
"AcceptedStates": {
"T1": "ArithmeticOperator",
"T2": "ArithmeticOperator",
"T3": "ArithmeticOperator",
"T4": "ArithmeticOperator"
},
"Table": {
"T0": {"+": "T1", "-": "T2", "*": "T3", "/": "T4"},
"T1": {"+": "", "-": "", "*": "", "/": "" },
"T2": {"+": "", "-": "", "*": "", "/": "" },
"T3": {"+": "", "-": "", "*": "", "/": "" },
"T4": {"+": "", "-": "", "*": "", "/": "" },
}
}실제로 사용해보겠습니다.
초기 상태 T0에서 "-"만 주면 어떻게 작동할까요? T2로가서 Accept 돼야 합니다. 잘 분류되는지 확인해봅시다.
# DFA를 ARITHMETIC_OPERATOR로 초기화
dfa = FiniteAutomaton()
dfa.LoadTransitionTable(ARITHMETIC_OPERATOR)
# DFA 사용
print("---TEST---")
print("Input이 \"-\"일 때")
input_char = "-"
nextState = dfa.PeekNextState(input_char)
dfa.SetState(nextState)
print("Accepted State입니까?", dfa.IsAccepted())
print("나의 현재 State:", dfa.GetState())
print("토큰이 {}로 분류되었습니다.".format(dfa.GetToken()))
# dfa를 사용을 마쳤으면 종료
dfa.Reset()
print("-----------")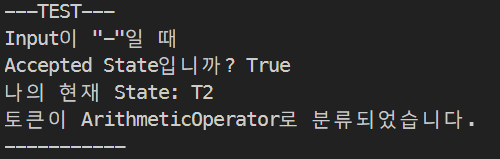
잘 분류됩니다.
초기 상태 T0에서 "ㅁ"만 주면 어떻게 작동할까요? 정의되지 않은 Symbol이 나와서 오류가 나야 합니다.
# DFA 사용
print("---TEST---")
print("Input이 \"ㅁ\"일 때")
input_char = "ㅁ"
nextState = dfa.PeekNextState(input_char)
dfa.SetState(nextState)
print("Accepted State입니까?", dfa.IsAccepted())
print("나의 현재 State:", dfa.GetState())
print("토큰이 {}로 분류되었습니다.".format(dfa.GetToken()))
# dfa를 사용을 마쳤으면 종료
dfa.Reset()
print("-----------")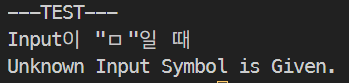
잘 오류가 납니다.
이 코드를 조금만 수정하면 바로 Lexical Analyzer가 완성됩니다!
Lexical Analyzer Pseudo Code
-
Input파일을 읽는다
inputString = 소스코드파일.Read() -
dfa.Reset() -
dfa.PeekNextState(inputString의 제일 앞의 문자 Pop) -
다음 State가 Reject 상태인지 확인
(YES) 현재 State가 Accept 상태인지 확인 후 맞다면 Token으로 분류하고 2.부터 다시 진행한다.
(NO) 3. 과 4. 반복
이러한 것 말고도 고려해야 할 것들이 있습니다.
-
inputString을 모두 pop했으면 끝나야 됩니다,
-
더 이상 pop할 inputString이 없는데 dfa가 Accepted State가 아니면 오류입니다.
-
어떤 Token으로 분류할지 충돌이 나는 경우 우선순위를 주어서 해결합니다.
예를 들어서, 주어진 문자가 "int"인 경우 Token을 KEYWORD로 분류할지 IDENTIFIER로 분류할지 충돌이 날 수 있습니다. KEYWORD에 우선 순위를 주어서 먼저 KEYWORD로 한번 분류하도록 하면 간단히 해결할 수 있습니다. 토큰을 KEYWORD로 먼저 분류하려고 해 보고 성공하면 KEYWORD인 것이고 실패하면 뒤로 돌아가서 IDENTIFIER로 분류하려고 재시도합니다.
그러면 "int"와 같은 경우 KEYWORD에 우선순위가 있으니 KEYWORD로 분류가 되고 "intra" 같은 단어는 먼저 KEYWORD로 분류하려다가 "int" 뒤에 나오는 'r'이라는 문자 때문에 Reject가 되고 다시 IDENTIFIER로 분류를 해서 IDENTIFIER로 분류가 됩니다.만약 IDENTIFIER로도 분류가 실패하면 알 수 없는 단어를 준 것이기 때문에 오류인 경우입니다.
3. 문자열을 읽으면서 Symbol Table을 만듭니다
2. 에서 만든 Finita Automata로 input을 쭉 읽으면서 토큰 별로 분류를 합니다. 너는 A라는 토큰이야! B라는 토큰이야!라는 결과가 나왔으면 토큰과 분류된 문자열(Token Value가 필요할 수 있기 때문에 저장)을 파일에 저장합니다. 그 파일이 곧 Symbol Table이고 Syntax Analysis 단계에서 사용하게 됩니다.
예를 들어서, 다음과 같은 파일이 문자열로 주어줬다고 해봅시다.
int main(){
printf("Hello, World!\n");
}그러면 완성된 Lexical Analyer는 다음과 같은 Symbol Table을 만들 수 있어야 합니다.
<TokenName:VARIBLE,RAW_INPUT:int>,
<TokenName:WHITESPACE,RAW_INPUT: >,
<TokenName:IDENTIFIER,RAW_INPUT:main>,
<TokenName:PARENTHESES,RAW_INPUT:(>,
<TokenName:PARENTHESES,RAW_INPUT:)>,
<TokenName:BRACKET,RAW_INPUT:{>,
<TokenName:WHITESPACE,RAW_INPUT:\n\t>,
<TokenName:IDENTIFIER,RAW_INPUT:printf>,
<TokenName:PARENTHESES,RAW_INPUT:(>,
<TokenName:LITERALSTRING,RAW_INPUT:"Hello, World!\n">,
<TokenName:PARENTHESES,RAW_INPUT:)>,
<TokenName:SEMICOLON,RAW_INPUT:;>,
<TokenName:WHITESPACE,RAW_INPUT:\n>,
<TokenName:BRACKET,RAW_INPUT:}>실용적인 Compiler 구현법
보통 손으로 정규식을 NFA로 변환하고 다시 DFA로 변환하지 않습니다. 귀찮고 실수하기 쉽고 무엇보다 알고리즘이 존재하는데 굳이 손으로 할 필요가 없기 때문입니다. 하지만 과정을 보여주기 위해 손으로 작성해봤습니다. 저도 강의 때 이렇게 배웠는데 알고리즘을 이해하는데 큰 도움이 됐습니다.
어쨌든 Thomspon Construction, Subset Construction과 같은 자동화된 수단이 있기 때문에 그 알고리즘을 기반으로 잘 포장시켜서 성공한 프로그램들이 여러 개 있습니다. 찾아보면 정규식을 NFA, DFA로 만들어주는 https://cyberzhg.github.io/toolbox/nfa2dfa와 같은 사이트도 있습니다. 그리고 보통 컴파일러의 Lexical Analyzer를 구현하기 위해서 Lex나 Flex라는 툴도 많이 사용합니다. Lex는 원래의 Original 버전이고 그것을 모방해서 Flex가 나왔습니다. 거의 똑같지만 Flex가 더 최신 버전이라서 Flex를 더 많이 사용하는 것 같습니다. 둘 다 C언어가 기반이 됐기 때문에 C언어를 안다면 금방 사용법을 익힐 수 있습니다. 비슷하게 Java를 기반으로하는 툴도 있고 찾아보면 여러 툴들이 있습니다.
- Icons made by monkik from www.flaticon.com